1.闲扯
某晚,洗漱后正准备休息,客服电话过来,某客户DB很卡,运维快炸了。让我赶紧看一把。
和客户简短沟通后了解到,客户是一个娱乐平台,业务高峰期是晚上六七点到晚上十一二点,我一看时间刚好是21:00左右,那么这时候应该是业务负载最高的时候,客户还说到,基于主键的point query都非常卡顿,一条select * from t where pk=xxx都需要四五秒才能执行完。一想point query都卡出翔了,肯定还是情况蛮严重的,就好好看看呗。
2.故障现场
登录主机,首先看看IO和CPU怎么样了:
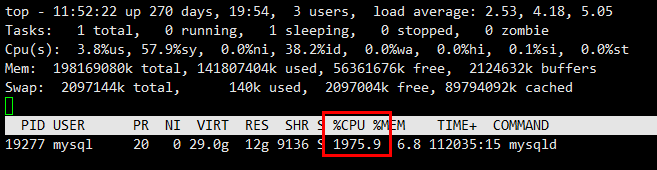
那么io呢

很明显,IO没啥负债,CPU跑爆了,从以往ORACLE经验来看,应该是逻辑读太高了,有点像oracle的cbc等待,这是第一反应。
为什么cpu负载不是100%,而接近2000%.这也很好理解啊,因为mysql是一个单进程多线程的架构:

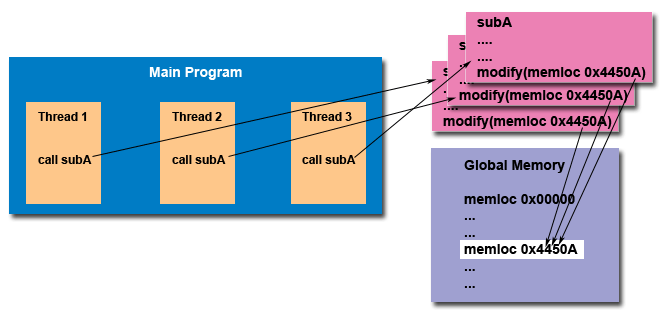
进程:进程有两个独立的特点:
1.资源(IO/内存/文件)所有权->(进程或任务)
2.执行/调度(cpu)->(线程或轻量级进程)
从进程这两个特点我们可以看出,进程内部的每个线程都可以同时被分配到cpu的计算资源,也就是说线程之间是真正的并行,而不是并发(python的多线程除外)。
如何向五岁的小孩讲解并发和并行:

也就是说,当时的mysql是真正的用到了多核计算资源,并且这些计算资源的使用率之和达到了1900%。好了,我们继续。
登录DB
我统计了一下mysql.slow_log里面的慢查询:
短短两三个小时,查询时间超过3s的有7万条sql

两三个小时期间,查询时间超过10s的有1万条sql

每一次查询,扫描记录行数超过100W的有100条

最慢的查询超过一分钟,可能很多同学感觉查询1分钟也没啥奇怪的,可是,这是一个oltp系统啊,怎么扛得住1分钟的查询?一分钟的查询耗费了多少宝贵的cpu/内存/io资源。
数据库性能非常恶劣,在崩溃的边缘。
咋办呢
数据库都这幅鸟样了:
1.停服优化?
这个肯定是不能接受的,虽然玩家的体验没那么爽,但也不能让别人玩的正嗨时停掉,让人绝望。这样玩家肯定跑掉很多,那就尴尬了。
2.带病运行,kill慢查询保业务?
这个可能也是唯一一条途径了。
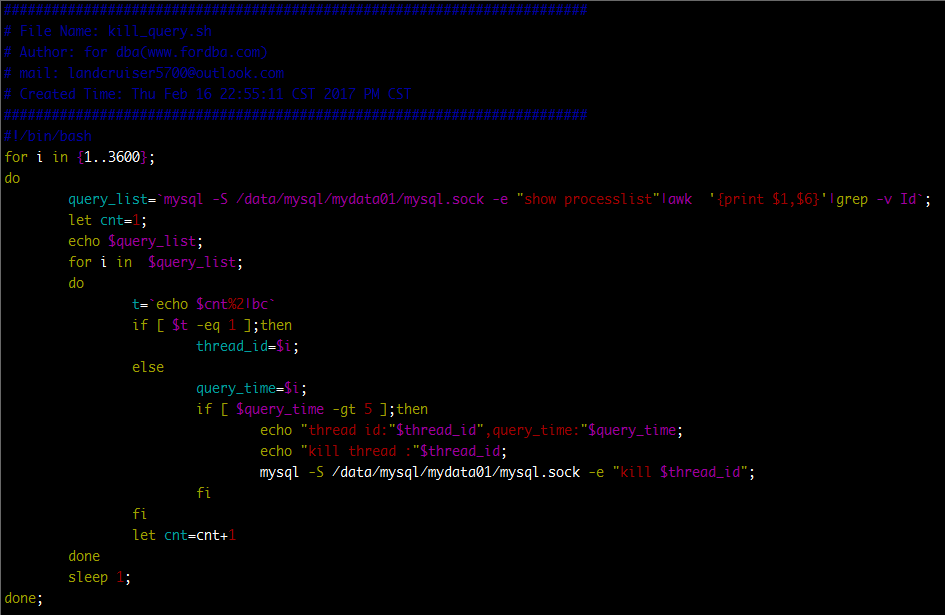
动作一
每过5秒去数据库中检查一次,超过10s的查询全部kill掉,实现脚本如下(截图中时间参数不一定相符):
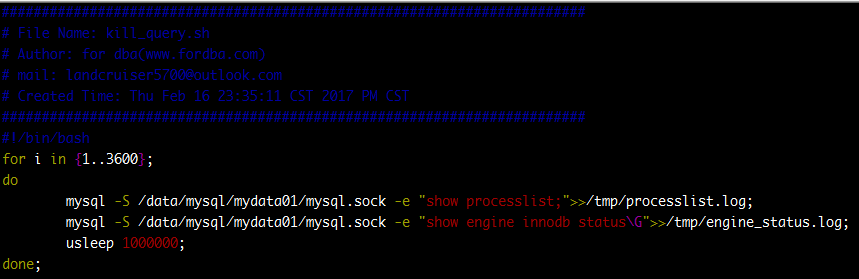
动作二
mysql也没有oracle里面的ash视图,只能手动抓拍了,每一秒钟去DB里面采一次processlist和engine innodb status:
脚本先采集一些信息,完了在分析,没事,抓几条sql出来看看执行计划啥的:

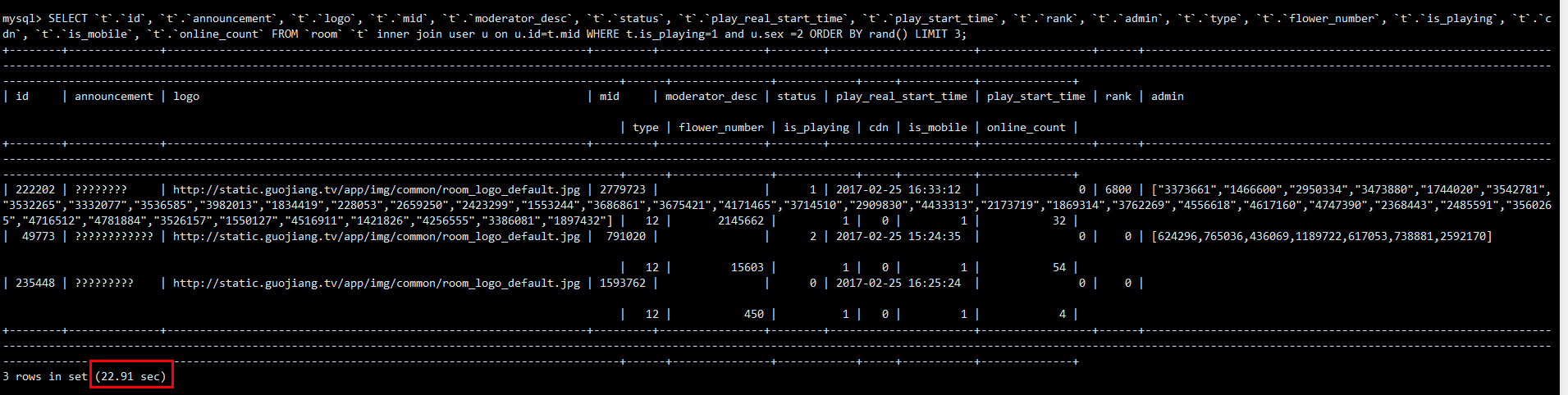
同样的sql,快的时候,一秒不到出结果,慢的时候20s+
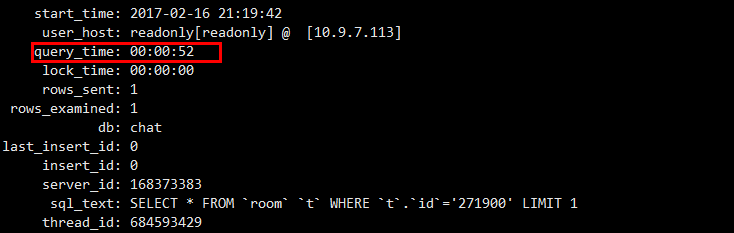
这种基于主键的查询都要50s
我真的可能执行了假SQL!!!!
分析抓拍
从几十分钟的processlist抓拍来看,发现一个比较有特点的snapshot,
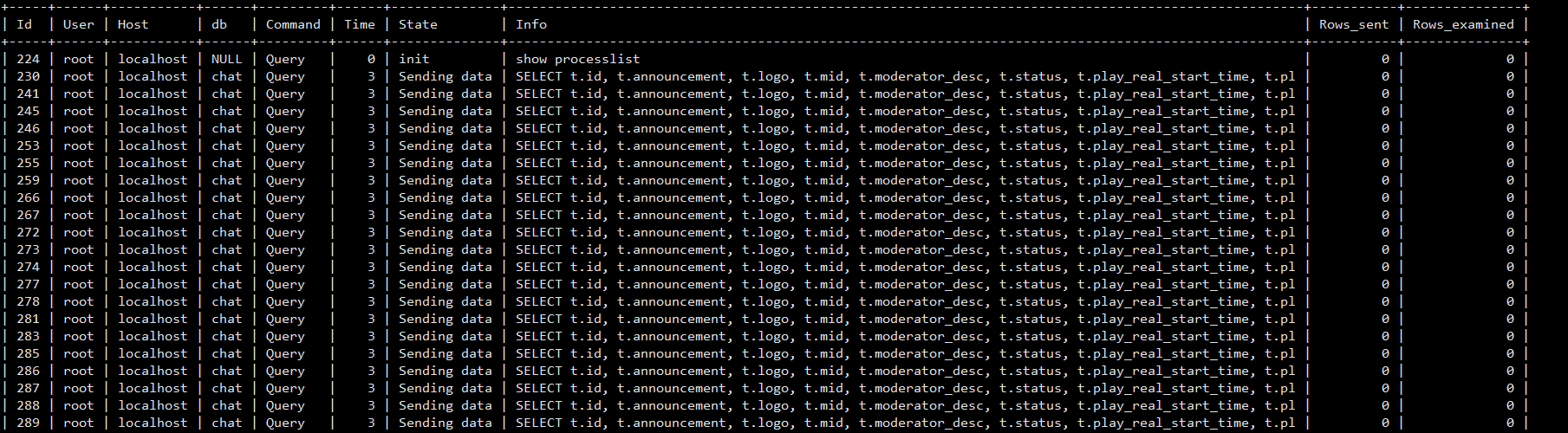
每次看到这条sql刷屏,完了后面的抓拍就是其他查询一直堵着,连接数暴涨,一直涨到近千。也很奇怪,这条sql都是几乎都是同时发来,只要这条sql并发来,就堵起来了。
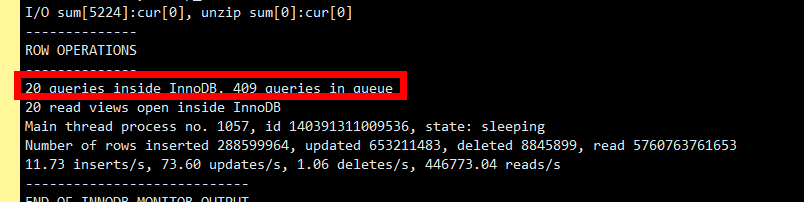
看完这个,大家心里可能有些数了,这个连接数堆积和这篇文章介绍的故障类似:
MySQL数据库大量sleeping before entering InnoDB故障诊断
其实这个道理也很好理解,看看mysql内核架构就知道了:
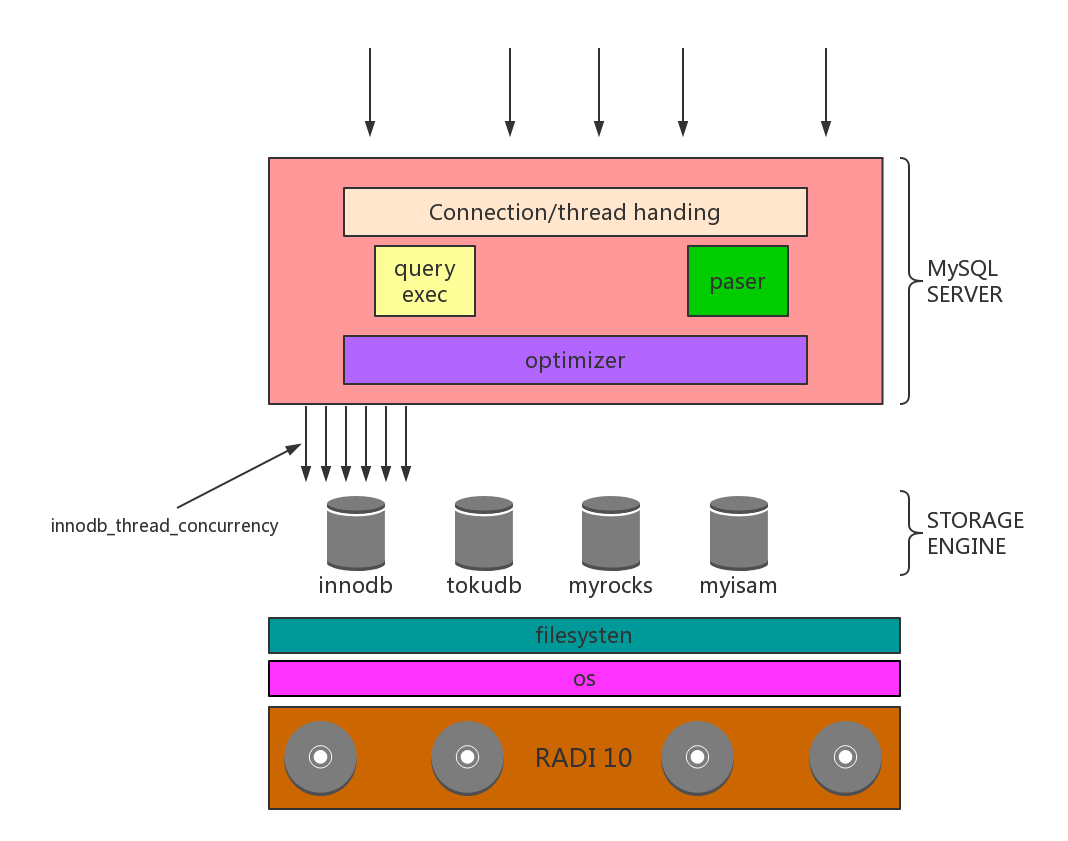
MySQL的这个参数innodb_thread_concurrency,这个参数控制同时有多少个线程可以进入innodb内部存取数据,如果进入innodb内部的这些线程一直陷在里面不出来,那么其他线程只有等待,一直不出来,其他线程也只有一直等待,这样就形成了队列效应。这也就好解释为什么基于主键的point query也需要50s了,因为查询的99%的时间都在排队,而不是真正的计算。
既然找出了问题sql,立刻通知开发check该sql,经过确认发现,该sql确实有问题,立刻修改上线。
第二天晚上,我在业务高峰期给客户保障了几个小时,再也没有出现CPU跑爆炸的情况,也没有出现Point query长达几十秒的情况。
深入看看
事情到了这里,看似已经过去了,可以收工了,客户也很满意。作为DBA,有时候还是要深入探讨一下,特别是有强迫症的DBA,不深入搞搞,心里憋得慌。
first of all,看看sql的执行计划有没有问题呢:

看到这条sql,首先不论执行计划怎么样,写法上本身就有很多问题的,oltp环境不是特别适合搞join,还有那个order by rand()。真的有些过分啊。
再来看看执行计划
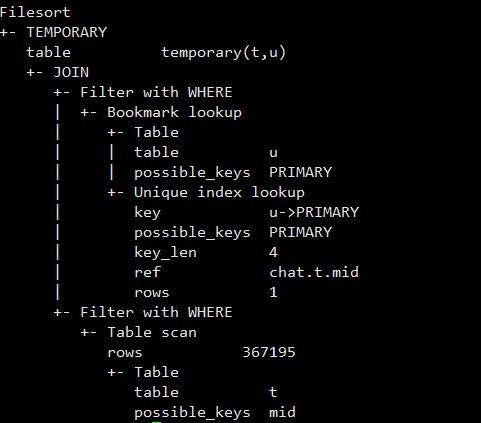
这个room表走了全表扫描,第一感觉有些不合适,是不是没有索引?是不是优化器缺陷,选错了执行计划?
你看了下面这些信息,你会感觉优化器没走错执行计划,mysql这次很聪明。

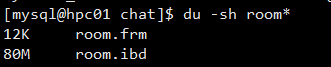
看了这些数据,不言而喻,执行计划是没有问题的。扫描80MB的数据,以Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz的计算能力,也是轻松加愉快的事情。
那么问题来了,这条SQL单次执行,非常快,并发执行,卡出翔,这又是为什么呢?难道仅仅只是全表扫描这么简单吗?
看来只能放大招了,用下神器:
perf(Perf — Linux下的系统性能调优工具)
这个工具可以看到进程最消耗资源的调用,从而帮助我们定位问题,立刻用起来啊。
perf top -K -p `pidof mysqld`
将问题SQL10个并发一起跑,得出以下结果:

很明显,最消耗资源的是_init_free,__libc_calloc和row_sel_store_mysql_field_func,那么这三个函数是干嘛的呢。
row_sel_store_mysql_field_func是mysql将innodb的行格式转换为mysql server层统一使用的格式,这个过程就是做convert,也就是纯CPU计算,CPU消耗大,也还可以理解。
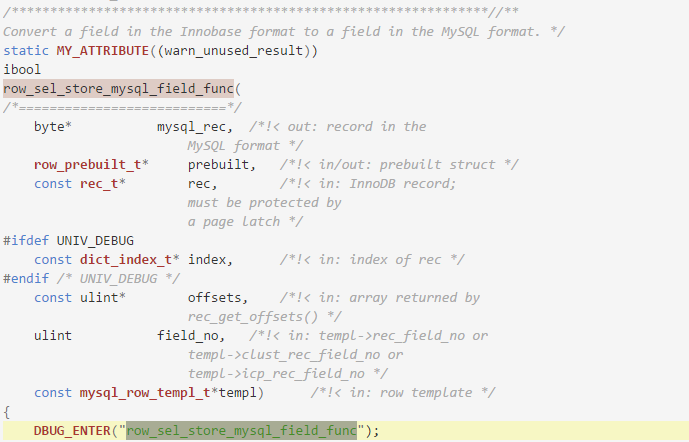
这个_int_free和__libc_calloc这两个是什么东西呢 ,又不像普通函数。这其实是两个系统调用,分别对应我们在C语言中非常熟悉的malloc和free,这两个函数就是内存的分配和释放。

难道内存的分配和释放还成了瓶颈?同样的数据,同样并发数的SQL,放到同版本的percona下面,结果如下:
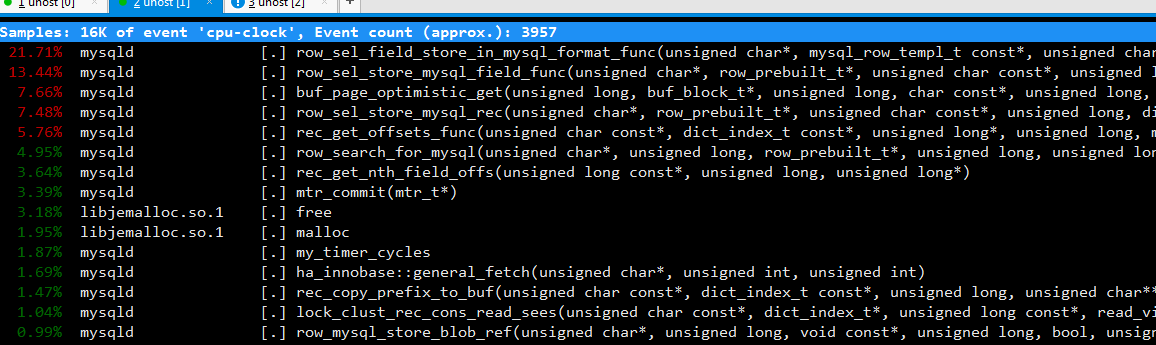
很明显,现在主要的瓶颈不在内存分配和释放,而是mysql做行格式的convert。这个时候,即使20个并发一起跑,响应时间平均也只需要2s左右,相比标准版mysql的平均响应20s好多了。这时最消耗资源的虽然是mysql做convert,但这时才是好钢用在刀刃上,花钱花在裉节儿上了。
这时候要注意的是,发生内存分配竞争的不是innodb buffer pool ,而是每个线程的局部内存区域,也就是每个线程在做buffer get的时候,需要把Buffer pool的数据取到线程本地来计算,这时肯定要在本地开辟新内存和释放不再需要的内存。innodb buffer pool是预先开辟好的buffer chunk,由innodb自己管理,并不是随意释放和请求分配,一旦Buffer pool初始化好了,就不会变的。
为什么percona版本没有问题,oracle版本的mysql就有问题呢?因为percona是使用的jemalloc内存分配器,而oracle的mysql是用的glibc c标准的内存分配器:ptmalloc。
到这里是否还有必须再深入一下,为什么ptmalloc分配比jemalloc弱一点呢?是不是所有场景下jemalloc都比ptmalloc好呢?关于内存分配器,社区还有tcmalloc也比较流行,。
ptmalloc 是glibc的内存分配管理 tcmalloc 是google的内存分配管理模块 jemalloc 是BSD的提供的内存分配管理
刨根内存分配器
看到这里,可能很多同学就疑问了,ptmalloc到底哪里不好了,高并发下面导致这么严重的性能问题。我们不得不来看看ptmalloc和jemalloc内存分配的一些原理。
首先我们看看下面这幅图。
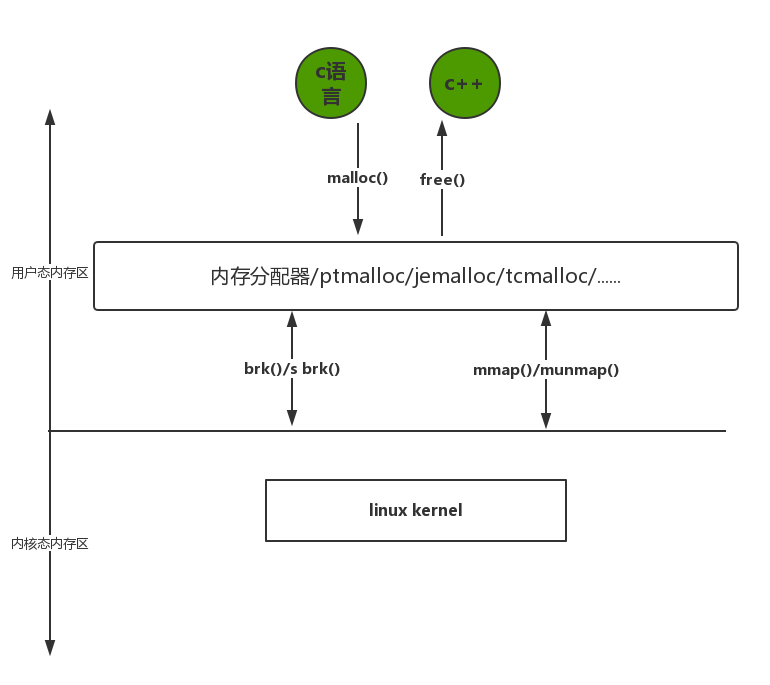
看到这幅图,我们需要明白几点的是,应用程序看到的内存是一段连续的内存,注意连续二字。其次至于应用程序怎么拿到内存,那是内存分配器做的事情。
熟记linux内存的两个特点
1.进程用的是虚拟内存(虚拟内存怎么和物理内存对应,那是页表干的事情)
2.内核分配物理内存(怎么管理物理内存,那是内核做的事情)
ptmalloc
ptmalloc 实现了 malloc(),free()以及一组其它的函数.以提供动态内存管理的支持。分配器处在用户程序和内核之间,它响应用户的分配请求,向操作系统申请内存,然后将其返回给用户程序,为了保持高效的分配,分配器一般都会预先分配一块大于用户请求的内存,并通过某种算法管理这块内存。 来满足用户的内存分配要求, 用户释放掉的内存也并不是立即就返回给操作系统,相反,分配器会管理这些被释放掉的空闲空间,以应对用户以后的内存分配要求。也就是说,分配器不但要管理已分配的内存块,还需要管理空闲的内存块,当响应用户分配要求时, 分配器会首先在空闲空间中寻找一块合适的内存给用户, 在空闲空间中找不到的情况下才分配一块新的内存。
那么问题来了,MySQL是一个单进程多线程的程序,我们也知道了,线程可以独立分配到CPU的计算资源,每个线程可以同时运行在不同的CPU之上,假如我们多个线程同时请求内存分配或者释放,有没有可能导致临界资源问题呢?前面我们说到了,我们的应用程序看到的是一段连续的内存,如果多个线程同时抢内存的时候,说白了就是在一条线上确定我抢到的虚拟内存起始位置和结束位置,如果不加以控制,很可能导致抢到的位置有重叠部分,这就尴尬了。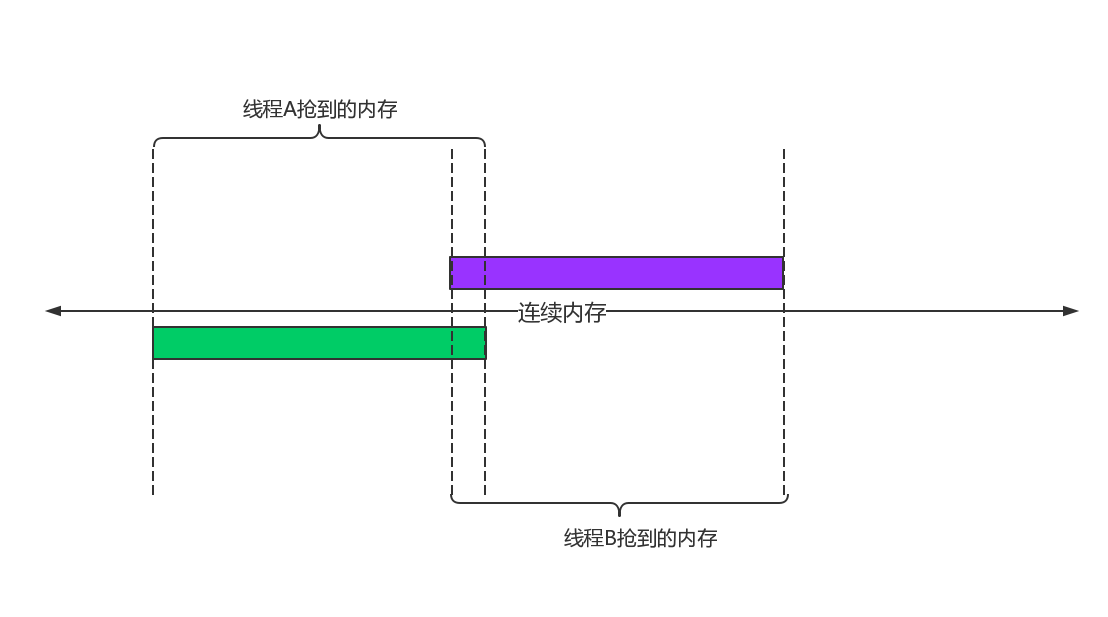
如图这样肯定是不安全的,肯定还是要搞个锁来控制一下。ptmalloc最初为了支持并发申请内存,引入了锁这个东东,加了锁,那么就不会出现尴尬的局面,每次申请内存之前,线程都必须拿到锁。但是有锁就有竞争啊,锁竞争啊,烧CPU啊,CPU空转啊。怎么办?如何缓解这个问题呢?
缓解锁竞争的常用模式就是把锁的粒度细化,ptmalloc推出的改进版就是用多个锁来缓解全局大锁的 lock contention。老外这么说的:
They tried pushing locks down in their allocator, so that rather than using a single allocator lock, each free list had its own lock
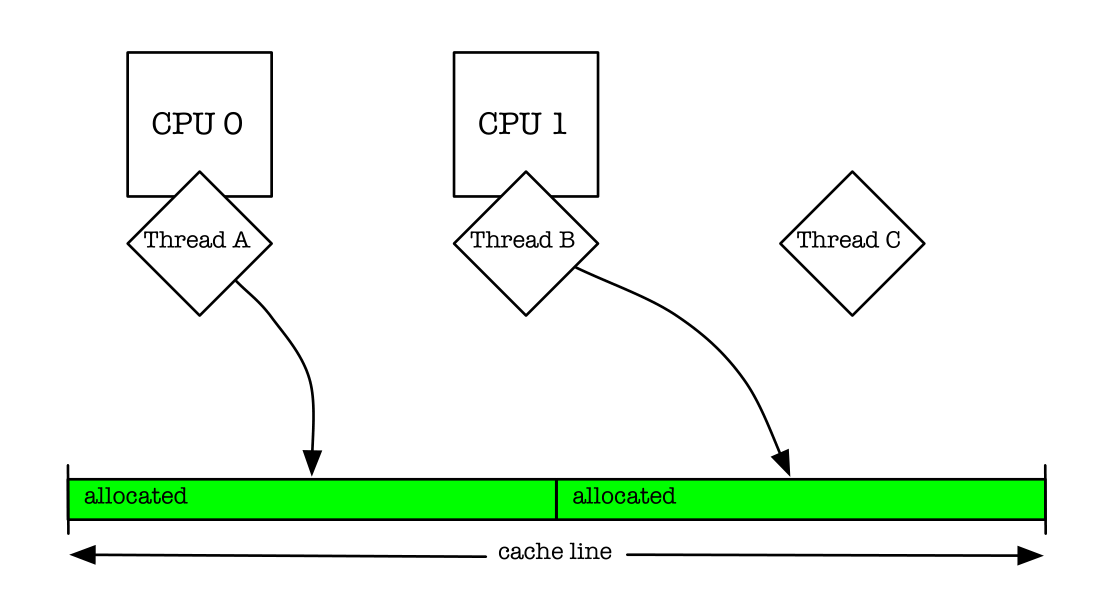
假如以前用一个锁控制一个进程内部多个线程申请内存,现在用10个锁来细粒度控制。看起来已经完美解决。
多线程申请内存前拿锁过程是这样的,当某一线程需要调用 malloc 分配内存空间时,该线程先查看线程私有变量中是否已经存在一个分配区, 如果存在, 尝试对该分配区加锁, 如果加锁成功, 使用该分配区分配内存,如果失败, 该线程搜分配区索循环链表试图获得一个空闲的分配区。 如果所有的分配区都已经加锁,那么 malloc 会开辟一个新的分配区,把该分配区加入到分配区的全局分配区循环链表并加锁,然后使用该分配区进行分配操作。在回收操作中,线程同样试图获得待回收块所在分配区的锁, 如果该分配区正在被别的线程使用, 则需要等待直到其他线程释放该分配区的互斥锁之后才可以进行回收操作。高并发下面申请内存多了一个搜索过程,这个搜索过程就是cpu不断的对不同的锁做cas或者tas的动作(原子指令compare_and_swap/TestAndSet),这是非常耗费资源的,搜索过程可长可短,取决于当时的负载量。如果负载较高,每次都需要把所有的锁都去遍历一次,结果还拿不到锁,还要去自己再开辟一个,这只能说比全局大锁稍微解决了一点问题,没有根治问题。问题就在于这个寻锁过程。我们对多个锁做cas或者tas和对同一个锁做cas或者tas,效果相差不多。
看个趣图,就能感觉到问题所在(点击红色字体查看):
排队的尴尬
等待的过程是非常难熬的,就像两个人谈恋爱,女孩子始终等待男孩给她发微信,两分钟看一次手机,微信咋还没响呢?非常的痛苦。等来等去没等到,最后索性主动联系男孩或者找闺蜜啥的撩起来。(哈哈哈,纯属个人YY,锁等待差不多意思,帮助大家理解)
jemalloc
好了,那我们如何来缓解一下这个痛苦的等待过程呢?BSD那帮老大哥想了这么个办法来缓解问题:
1.我们将内存分配划区,每个区一个锁(区的个数为处理器个数的4倍,假如16核的处理器,那么就有64个区)
2.线程申请内存之前拿锁不再是挨个去做cas或者tas,而是使用round-robin方式把每个线程分配到不同分区,之所以不使用hash来得到分区号,因为hash冲突会增大锁争用概率,使用round-robin方式可以保证,每个区被分派到的线程数大约相同。如果使用线程号来做hash运算,得出区号,但是线程号是一个伪随机值,我们也很难处理hash冲突,很有可能所有线程被hash到同一个区。
3.如果该区有其他线程已经占住锁了,那么就等,如果该区空闲,直接拿锁分配(这就减少了寻锁过程,找不到自己的区)

那么这种算法到底在高并发环境下,对内存分配和释放有多少效果呢,老外做过测试:

可以看出,jemalloc在多线程高并发环境下面,确实效率高出ptmalloc很多,而且很稳定,不会随着并发量上升而下降。

近期评论